Auto-annots Survey
## 1. Deep extreme cut: From extreme points to object segmentation, Kevis et al_ CVPR2018 ##

(1) paper and code
paper link: https://arxiv.org/abs/1711.09081
code(pytorch): https://github.com/scaelles/DEXTR-PyTorch
(website) [http://people.ee.ethz.ch/~cvlsegmentation/dextr/]
(2) problem range
target: single image
testing datasets: COCO, Pascal VOC, GrabCut, Davis 2016, Davis 2017
(3) architecture
(inference) input: four extreme points(left-most, right-most, top and bottom)
(refinement)input: the above four points+ one extra point
(4)Implement details:
Balance loss(cross-entropy)
(5) results:
1> Obtaining state-of-the-art results in all scenarios.
2> Reducing labeling costs by a factor of 10.
##================================================== ##
## 2. Annotating Object Instances with a Polygon-RNN_Liuis et al_ CVPR 2017 ##
(1) paper and code:
paper link: https://arxiv.org/abs/1704.05548
(2) problem range:
1> support type: instance segmentation
2> dataset:
Training and validation: Cityscapes(training set)
Inference: Cityscapes(validation set)
Generalization: KITTI
3> input: first vertix, two previsous vertixes
output: all the vertixes that form a cicle(for a specific object instance)
(3)workflow

(4) implement details:
1> Architecture: CNN+LSTM
CNN: serving as an image feature extractor
RNN: decoding one polygon vertex at a time
2> backbone: VGG16
(5) results:
1> achieving demanding accuracy: very few clicks
2> speed-up factor: 4.74 (compare with human annotator)
(6) advantages and limitations:
1>advantage:
interactive(can be refined): compare with the CNN based segmentation method( including DeepMask and SharpMask)
2> disadvantages:
The performance for the large objects are not good as DeepMask and SharpMask( may due to the different backbone)
It ask more vertixes to form a circle for the instance( memory consuming)
##================================================== ##
## 3. Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++_David Acuna et al_CVPR2018 ##
(1) paper and code:
paper link: https://arxiv.org/abs/1803.09693
(org) code(tensorflow): https://github.com/davidjesusacu/polyrnn-pp
web page: http://www.cs.toronto.edu/polyrnn/
(2) problem range:
same with 2. polygonrcnn(above)
(3) workflow:


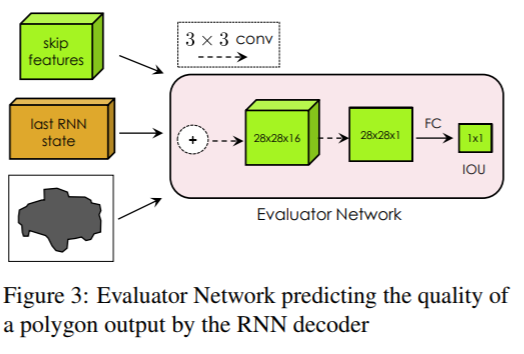
(4) implement details:
1> design a new CNN encoder-architecture
2> training the model with Reinforcement Learning
3> increase the output resolution using a Graph Neural Network, allowing the model to annote the high-resolution objects in image.
(5) results:
1> accuracy: improve 10% mean IOU compared with polygon_rnn
2> click: 50% fewer clicks by annotators compared with polygon_rnn
(6) limitations:
1> can't handle objects that contain holes
2> can't hanlde the occluded cases for multi-objects.
##============================================== ##
## 4. One-Shot Video Object Segmentation_ Sergi Caelles et al_CVPR2017 ##
(1) paper and code:
1>paper link: https://arxiv.org/abs/1611.05198
2>code(caffe, pytorch, tensorflow): https://github.com/scaelles/OSVOS-TensorFlow
(2) problem range:
input: the gt_segmentation of the first frame and the video sequence.
output: Segment the rest of the video sequence.
(3) workflow:
Steps:
s1: Pre-trained image-feture(for classification) on image-net
s2: fine-tuning object-segmentation on davis dataset
s3: over-fitting a specific object in the first frame of a video sequence

(4) implement details
(5) results
##=============================================== ##
## 5. DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks ##
(1)paper and code:
paper link: https://arxiv.org/abs/1605.07866
idea: Combining CNN and GrabCut
conclusion: Try PolygonRNN++ on Cityscapes first.
directions: doing a temporal PolygonRNN++
##================================================= ##
BoxSup
DeepLab
Seg_papers link: https://github.com/handong1587/handong1587.github.io/blob/master/_posts/deep_learning/2015-10-09-segmentation.md

(1) paper and code
paper link: https://arxiv.org/abs/1711.09081
code(pytorch): https://github.com/scaelles/DEXTR-PyTorch
(website) [http://people.ee.ethz.ch/~cvlsegmentation/dextr/]
(2) problem range
target: single image
testing datasets: COCO, Pascal VOC, GrabCut, Davis 2016, Davis 2017
(3) architecture
(inference) input: four extreme points(left-most, right-most, top and bottom)
(refinement)input: the above four points+ one extra point
(4)Implement details:
Balance loss(cross-entropy)
(5) results:
1> Obtaining state-of-the-art results in all scenarios.
2> Reducing labeling costs by a factor of 10.
##================================================== ##
## 2. Annotating Object Instances with a Polygon-RNN_Liuis et al_ CVPR 2017 ##
(1) paper and code:
paper link: https://arxiv.org/abs/1704.05548
(2) problem range:
1> support type: instance segmentation
2> dataset:
Training and validation: Cityscapes(training set)
Inference: Cityscapes(validation set)
Generalization: KITTI
3> input: first vertix, two previsous vertixes
output: all the vertixes that form a cicle(for a specific object instance)
(3)workflow

(4) implement details:
1> Architecture: CNN+LSTM
CNN: serving as an image feature extractor
RNN: decoding one polygon vertex at a time
2> backbone: VGG16
(5) results:
1> achieving demanding accuracy: very few clicks
2> speed-up factor: 4.74 (compare with human annotator)
(6) advantages and limitations:
1>advantage:
interactive(can be refined): compare with the CNN based segmentation method( including DeepMask and SharpMask)
2> disadvantages:
The performance for the large objects are not good as DeepMask and SharpMask( may due to the different backbone)
It ask more vertixes to form a circle for the instance( memory consuming)
##================================================== ##
## 3. Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++_David Acuna et al_CVPR2018 ##
(1) paper and code:
paper link: https://arxiv.org/abs/1803.09693
(org) code(tensorflow): https://github.com/davidjesusacu/polyrnn-pp
web page: http://www.cs.toronto.edu/polyrnn/
(2) problem range:
same with 2. polygonrcnn(above)
(3) workflow:


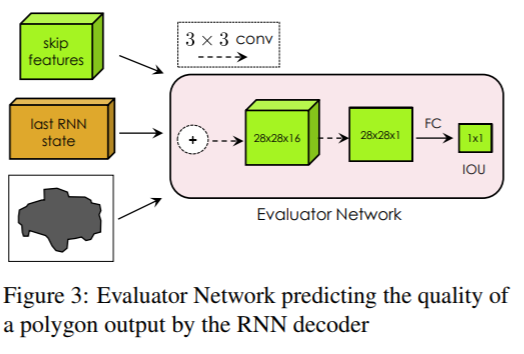
(4) implement details:
1> design a new CNN encoder-architecture
2> training the model with Reinforcement Learning
3> increase the output resolution using a Graph Neural Network, allowing the model to annote the high-resolution objects in image.
(5) results:
1> accuracy: improve 10% mean IOU compared with polygon_rnn
2> click: 50% fewer clicks by annotators compared with polygon_rnn
(6) limitations:
1> can't handle objects that contain holes
2> can't hanlde the occluded cases for multi-objects.
##============================================== ##
## 4. One-Shot Video Object Segmentation_ Sergi Caelles et al_CVPR2017 ##
(1) paper and code:
1>paper link: https://arxiv.org/abs/1611.05198
2>code(caffe, pytorch, tensorflow): https://github.com/scaelles/OSVOS-TensorFlow
(2) problem range:
input: the gt_segmentation of the first frame and the video sequence.
output: Segment the rest of the video sequence.
(3) workflow:
Steps:
s1: Pre-trained image-feture(for classification) on image-net
s2: fine-tuning object-segmentation on davis dataset
s3: over-fitting a specific object in the first frame of a video sequence
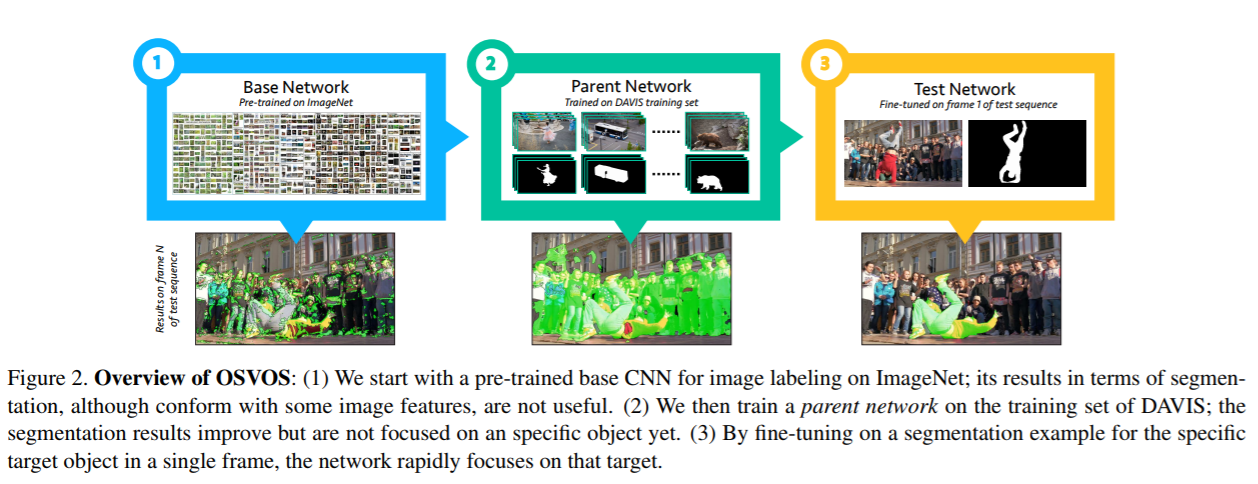
(4) implement details
(5) results
##=============================================== ##
## 5. DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks ##
(1)paper and code:
paper link: https://arxiv.org/abs/1605.07866
idea: Combining CNN and GrabCut
conclusion: Try PolygonRNN++ on Cityscapes first.
directions: doing a temporal PolygonRNN++
##================================================= ##
BoxSup
DeepLab
Seg_papers link: https://github.com/handong1587/handong1587.github.io/blob/master/_posts/deep_learning/2015-10-09-segmentation.md

Comments
Post a Comment